身份识别系统所用到的算法是光谱采样结构子空间特征(4SF)算法,它是一种基于统计学习的算法研究。原本用于研究人口统计资料和年纪增长对人脸识别性能的影响。4SF相比其它技术而言优势在于使用的面部特征描述和特征提取在现代脸部识别算法中具有很好的代表性。不仅如此,4SF还通过统计学习对准确性进行了很大程度的改进,这让OpenBR像异构面部识别那样在特定的匹配问题中具有训练自己的能力,从而区别于其他商业系统。
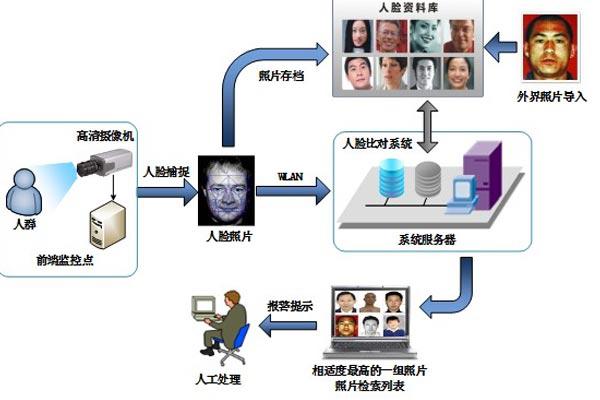
在对4SF算法与其他三种已有的身份识别系统面部识别算法分别产生的模板大小和准确性进行对比中获得结论:OpenBR拥有min的模板。在准确性方面,虽然有些商业系统在一些经典的面部识别数据下的表现优于4SF,然而在一些异构面部识别数据下的准确率却不然。这也体现出了产生新问题时可以训练系统的好处。OpenBR整体流程图如图所示。
1正脸检测
OpenBR对OpenCV级联分类框架进行了封装,并提供了基于Casecade(FrontalFace)级联分类器的正脸识别方法。身份识别系统对于眼睛的检测,使用的是基于C++、接口为ASEF的人眼识别方法ASEFEyes。ASEF即采用平均合成准确滤波的方法进行人眼定位。在训练中利用输入样本图片和合成输出结果,在频域上构造相关滤波器,然后将多个滤波器进行平均,获得的相关滤波器,这样采用训练的滤波器进行定位获得了比较理想的结果。
2归一化
在这里借助检测到的眼睛位置来注册人脸,并通过仿射变换完成严格的旋转和缩放。也是说人脸基于人眼位置做旋转扭正。在提取局部二进制时遵循光照预处理步骤。预处理使得在不同亮度、人脸图像旋转角度、拍摄角度、背景、光照位置等条件下获得的图像更加一致。当然这些因素的影响只会被削弱,而不会被完全消除,尤其是当人脸方向不一致时,身份识别系统会使人脸中所有元素的位置存在很大的不同,从而造成对人脸的识别异常的困难。
3特征描述
此处基于密集的网格提取LBP和SIFT特征来采样人脸。LBP的提取是通过6×6的滑动窗口每次对8×8像素的窗口提取局部二进制模型的直方图。SIFT的提取是从一个10×10的网格中采样一百个SIFT描述符,每个描述符半径为12像素。再利用PCA(主成分分析)分解保留95%的方差来压缩每个局部区域,随即描述符被投射到相应的特征空间,然后规范化到L2范数单元。
图流程图
4特征提取
身份识别系统在这一步要做的是加权谱抽样,也是将每个区域的特征向量连接起来,同时在各个维度的方差上执行随机采样的加权。在本文中提取12维特征,每个维数相当于整体特征空间的5%,然后使用LDA(线性判别分析)学习每一个随机样本的空间特征,这样可以使对面部特征向量的辨别力获得提高。然后,描述符再一次连接到一起并规范化到L1范数单元。发现在空间投影进行规范化可以大大的提高在许多识别场景模式下的准确性,这与观测结果一致。
5特征对比匹配
这里要用到的L1byte距离度量可以达到先进的匹配速度,同时对于准确率的影响小到几乎可以忽略不计。这里使用L1范数正则化来比较特征向量,将向量转换为8位无符号整数。这是模板生成的结束一步。L1范数正则化通过向成本函数中添加L1范数,使得身份识别系统学习获得的结果满足稀疏化(sparsity),从而方便了特征提取。





